近日,第32届ACM国际多媒体会议在澳大利亚墨尔本圆满落幕。由中国科学技术大学自动化系於俊老师带队的中国科学技术大学与云知声共同组建的USTC-IAT-United团队在不同挑战赛道上累计荣获5项冠军、2项亚军,技术实力再获国际顶会认可。
ACM MM(ACM International Conference on Multimedia)作为计算机图形学与多媒体领域的顶级国际会议,不仅被中国计算机学会(CCF)评定为A类国际学术会议,更以其卓越的学术影响力和社会认可度而闻名。该会议携手全球领先的学术机构和知名企业,举办了一系列挑战性赛事,成功吸引了全球众多科研团队和创新型企业的踊跃参与。
在这场全球顶尖智慧团队间的激烈角逐中,联合团队表现出色,在多个挑战赛道上夺得5项冠军、2项亚军,其研究成果广泛涉及微动作分析、微表情检测与分析、人机交互与对话、多模态群体行为分析以及视觉空间关系描述和深度伪造检测等前沿领域。具体获奖情况如下:
(1)微动作分析挑战 ( MAC: ACM Multimedia 2024 Micro-Action Analysis Challenge )
微动作相比于普通动作,更能展现人物在日常交流中的心理情绪,带来更丰富的语义信息,对这些微动作进行精准检测对于多模态理解至关重要。然而,微动作通常持续时间短,且多种微动作可能同时出现,因而检测需要更多画面帧的输入来实现精细捕捉,这将导致巨大的显存负担和训练代价。
为应对这些挑战,团队提出了3D-SENet Adapter,其能够高效聚合时空信息,实现端到端的在线视频特征学习。此外,团队发现结合背景信息可显著提升对小尺度微动作的检测效果,为此,团队开发了交叉注意力聚合检测头,该模块集成特征金字塔中的多尺度特征,显著提升视频帧中微动作的检测精度。该方法相比基线模型极大提升了检测精度,并在两个赛道上分别取得了冠军与亚军的成绩,并且以论文形式在 ACM MM 会议上发表了研究成果。
(2)微表情挑战 ( Facial Micro-Expression Grand Challenge (MEGC) 2024 (CCS Task) )
微表情作为一种面部表情,与宏表情相对应,通常持续时间短,强度较低。同时微表情在现实中有着广泛的应用,如医疗、刑事侦察等。MEGC挑战赛的CCS (Cross-Cultural Spotting)赛道致力于选拔出通用性广泛、稳定性强的微表情识别方法,以推动该领域技术的发展与应用。
面对CCS赛道提出的挑战,团队选择使用基于光流的方法进行微表情识别,对每个视频抽取其光流特征,进而通过光流特征定位微表情发生的起始时间和结束时间。在生成微表情区间之后,采用边界校准方案,通过判断评估边界的变化程度来决定压缩或延展边界,使得产生的微表情区间边界更加准确。此外,团队采用特定的特征增强方案,主要通过LANet增强特征的表达能力和鲁棒性。最终团队在排行榜上取得了冠军,研究成果也以论文形式于
ACM MM 会议上发表。
(3)微表情挑战 ( Facial Micro-Expression Grand Challenge (MEGC) 2024 (STR Task)
)
在以往微表情研究中,检测和识别任务相对分离,存在很大的局限性。因此MEGC挑战赛的STR (Spot-then-Recognize)赛道提出了 “先检测后识别”的任务来整合两个环节,进而提升微表情分析的准确性和实用性。
针对STR赛道提出的挑战,团队整合VideoMAE V2框架、时间信息适配器(TIA)及多尺度特征融合检测头,以提升微表情定位与识别性能。主要采用 VideoMAE V2作为特征提取骨干网络,结合TIA增强视频特征提取能力,尤其是在处理微表情任务时。TIA通过引入时间深度卷积层,捕捉相邻帧的局部时间上下文,丰富当前时间步的表示。同时,构建多尺度图像金字塔,通过分类和回归分支组成的检测头,融合不同尺度的特征,使得模型能够同时捕捉从宽泛动作到细微变化的全范围动态,进而显著提高微表情识别的准确性。
团队方案在 STRS(Overall)评分中达到SOTA 的结果,并获得冠军,研究成果在ACM
MM会议上进行发表。这一成果不仅验证了团队方法的有效性,也为微表情识别技术的进一步发展提供了方向。
(4) 多模态群体行为分析挑战 ( MultiMediate: Multi-modal Group Behaviour Analysis for
Artificial Mediation )
在多人对话和人机交互领域,对人类的参与程度的评估至关重要。MultiMediate挑战赛中的Multi-domain engagment estimation赛道中旨在解决当前人工调解者的能力受限于行为感知和分析方面的进展不足,进而推动和衡量在多领域参与度估计这一关键社会行为感知与分析任务上的进展。
为应对这些挑战,团队深入探索Seq2seq模型在不同时间窗口下的潜力,并提出了一种双流AI-BiLSTM模型,该模型能够对齐并交互对话者特征,以实现更准确的参与度估计。通过从视觉(CLIP)、文本(XLM-RoBERTa)和语音(w2v-bert-2.0)中提取特征,能够更全面地理解和预测对话者的参与度。在建模过程中,团队参考了ALbef和VL-BERT的设计,最终选择了基于AI-BiLSTM的建模方法。在推理时,AI-BiLSTM在多人对话场景中的Concordance
Correlation Coefficient (CCC)提升了8%,相较于第二名领先了10%,方案在ACM
MM竞赛中得到了验证,并以明显的优势夺得了冠军。不仅展示了团队在人工智能领域的技术实力,也为未来的人机交互和对话系统的发展提供了新的可能性。
(5)深度伪造检测挑战 ( 1M-Deepfakes Detection Challenge )
Deepfakes挑战赛通过视听级检测任务,帮助区分真实视频和深度伪造视频,阻止深度伪造视频在网络上的传播,保护信息的真实性和可靠性。在Deepfakes任务中,细粒度感知和跨模态交互能力的提升至关重要。
为解决Deepfakes提出的挑战,团队提出了一种创新的局部全局交互模块(AV-LG模块),显著增强了模型的检测性能。该模块由局部区域内自我注意、全局区域间自我注意和局部全局交互组成。为了消除视频伪造检测中倾向于将真实样本预测为假样本的偏差,团队适当增加了真实样本的误差权重。此外,团队发现理解视频语义对于视频伪造检测并非必要,因此通过傅里叶变换将采样帧转换为频域,进一步提高了模型性能。通过这些技术的应用,不仅展示了团队在视频伪造检测领域的技术实力,也为未来的Deepfakes检测技术提供了新的可能性。最终获得本赛道冠军,研究成果通过论文的形式在
ACM MM 会议上呈现
(6)视觉空间关系描述挑战 ( Visual Spatial Description (VSD) Challenge )
Visual Spatial Description(VSD)挑战旨在解决视觉空间语义理解领域的相关问题,即通过让模型和系统生成准确的文本描述句子,来描述输入图像中两个给定目标对象之间的空间关系,进而推动计算机视觉和自然语言处理领域在空间关系理解与描述方面的研究进展。这有助于人机交互场景下智能设备理解用户意图,提升用户体验。
针对VSD提出的挑战,团队应用 Retrieval Augmented Generation (RAG)技术来指导多模态大型语言模型 (MLLM)完成
VSD
任务,并利用正负样本解决幻觉问题,进一步微调MLLM以增强语义理解和整体模型效能。该方案在VSD任务中的空间关系分类和视觉语言描述任务中都表现出更高的准确性和更少的幻觉错误,取得了令人满意的结果。同时,团队深入研究VSD与VSRC数据样本不平衡问题,运用样本级加权损失和重采样等策略,提高模型对低频对象关系的学习能力,确保了其在复杂数据环境下能够高效处理。这些策略为更高级的视觉空间描述任务铺平了道路,为计算机视觉和自然语言处理领域的未来研究和实际实现提供了有价值的见解。团队以论文形式在
ACM MM会议上发表了研究成果并取得了亚军。
此次斩获5冠2亚,既是云知声与中国科学技术大学紧密合作、持续探索人工智能赛道的成果,同时也是云知声AGI技术架构实力的有力证明。
作为国内AGI技术产业化的先行者,云知声依托其全栈AGI技术与产业布局,持续推动千行百业的智慧化升级。2023年5月,云知声发布山海大模型(UniGPT)以来,持续保持高速迭代,在 OpenCompass、SuperCLUE、MedBench、SuperBench、MMMU 等多项通用、医疗及多模态大模型权威评测中屡创佳绩,通用能力稳居国内大模型第一梯队,医疗大模型能力持续保持领先优势。以通用大模型为基座,云知声构建起一个覆盖医疗、交通、座舱等多场景在内的智能体矩阵,并逐步完成 “助手→同事→专家” 的自我演进,为智慧生活、智慧医疗、智慧交通等业务提供高效的产品化支撑,推动“U+X”战略落实,持续践行 “以通用人工智能(AGI),创建互联直觉的世界”的使命。
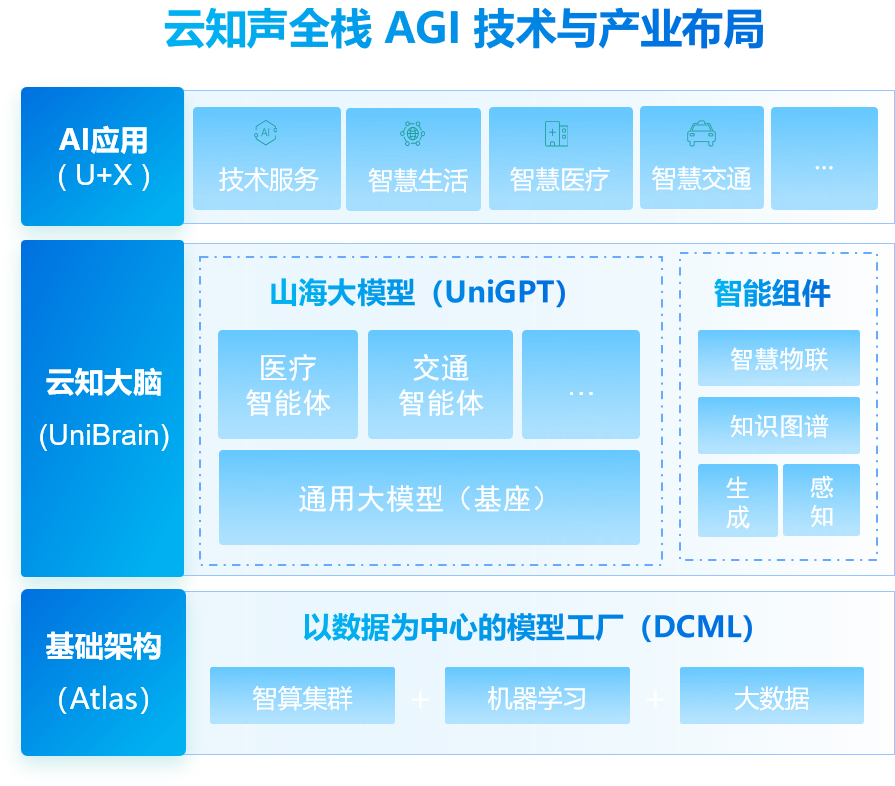
与中国科技大学的多模态技术合作,是云知声多模态智能体演进的重要组成部分。今年8月,云知声推出山海多模态大模型,通过整合跨模态信息,实现实时多模态拟人交互体验,进一步夯实了云知声AGI技术底座,推动山海大模型在各领域的广泛应用。
展望未来,云知声将继续携手中国科学技术大学等顶尖高校,共同加强人工智能基础理论探索与关键技术突破。我们将积极扩展AGI技术的应用场景,为智慧物联、智慧医疗等关键领域提供更为全面和深入的人工智能解决方案,致力通过人工智能技术,为各行各业带来革命性进步,实现以AGI赋能千行百业的宏伟蓝图。
免责声明:以上内容为本网站转自其它媒体,相关信息仅为传递更多信息之目的,不代表本网观点,亦不代表本网站赞同其观点或证实其内容的真实性。如稿件版权单位或个人不想在本网发布,可与本网联系,本网视情况可立即将其撤除。


